Under the terms of the Death in Custody Reporting Act, the Justice Department is required to collect information about everyone who dies in prisons and jails across the United States. The intention behind this effort is that, through the aggregation of details about people who die in the custody of thousands of law enforcement agencies, the resulting dataset could inform future life-saving policy changes.
Information about these deaths is typically not made public at a level of granularity that can provide insight into individual cases. However, due to what was likely a configuration error on a Department of Justice website, we obtained unprecedented access to the full, deanonymized dataset.
Through an analysis conducted earlier this year, we were able to show serious deficiencies across the dataset that fundamentally call into question its ability to provide accurate insights into trends in in-custody mortality.
This analysis is intended to rectify one of those problems in what, despite its myriad issues, is still likely the single best source for understanding in-custody death in the United States.
Each death listed in the dataset contains a “Manner of Death” field that displays a broad label of why someone died — like “Natural Causes” or “Suicide” — selected from a list of eight pre-selected categories. Deaths also contain a “Brief Circumstances” field, which contains a free-text description of the death, ranging from a single word to several paragraphs.
We discovered frequent mismatches between what was described in an entry’s “Brief Circumstances” and the “Manner of Death” that would logically follow from that description. For example, several "Brief Circumstances” describing capital punishment failed to be marked as executions.
Our goal with this project was to use a feedback loop of advanced artificial intelligence applications and manual, human labeling to assign an accurate “Manner of Death” to each death in the dataset based on what is present in the “Brief Circumstances" field. The resulting analysis provides both a clearer view of high-level trends of how people are dying in custody, as well as an assessment for how frequently the “Manner of Death” field in the dataset did not align with the other information provided.
What is the data?
In November 2024, a page on the website of the Bureau of Justice Assistance, the office in the Justice Department managing the in-custody deaths data collection, displayed several tables showing high-level summarizations of the data — such as counts of deaths by location type and manner.
While the tables did not display this information at the individual level, it was possible to click through a series of menus to make the visualization tool display the full, unredacted dataset. We downloaded that dataset on Nov. 20, 2024.
Justice Department officials did not respond when we asked if this exposure was intentional. However, shortly after we downloaded the data, the website was reconfigured to make subsequent downloads of the full dataset impossible.
The data we downloaded contained information about 25,393 deaths that occurred in prisons, jails, community correction programs, and while law enforcement officials were making arrests, stretching from Oct. 1, 2019 through Sept. 30, 2023.
An initial analysis of the dataset that we published this year showed several systemic problems.
Over 680 individuals who we know died in law enforcement custody based on information collected by advocacy groups or through media reports were missing. For comparison, we reviewed a list of 1,847 known deaths, largely focused in Louisiana, Alabama and South Carolina.
When deaths were listed, the descriptions were often inadequate. A random sample of approximately 1,000 deaths found that, in over 75% of cases, the “Brief Circumstances" did not meet the Bureau of Justice Assistance’s own standard for completeness.
For more information about how The Marshall Project acquired the dataset and what it contains, please refer to our previous post on the data analysis. The columns used for this analysis were “Manner of Death” and “Brief Circumstances.”
Analysis
Selecting records
The dataset we downloaded from the Bureau of Justice Assistance website included not only people who died in prisons and jails, but people who died while being arrested by police officers or sheriff's deputies, as well as people who died while participating in community corrections programs, like in a halfway house.
Since we wanted our analysis to focus solely on prisons and jails, we omitted the 3,716 deaths that were labeled as occurring during arrest, in community corrections, or where the location was unknown. That left us with 21,675 entries.
Broad categorization clustering
We started by clustering on the “Brief Circumstances” column, where we grouped text strings by their similarity to one another in order to reveal general trends in the dataset.
Embeddings turn clauses or sentences into meaningful vector representations in semantic space (i.e. two clauses with similar meanings should exist in roughly the same area of the vector space). Two “Brief Circumstances” with roughly similar meanings, like “heart attack” and “cardiac arrest,” should be close in distance in the vector space. We used OpenAI’s “text-embedding-3-large” embedding model to convert every entry in the “Brief Circumstances” column into a vector with a length of 3,072.
OpenAI’s model does not train on the data we entered into its system.
Next, we clustered these vectors in multi-dimensional space to understand the data’s shape and roughly how many clusters we should create. For this task, we used a Uniform Manifold Approximation and Projection (UMAP) technique to reduce the dimensionality of our space and then the HDBSCAN clustering algorithm to label each row in the dataset with an assigned cluster labeled by the algorithm. To evaluate the distance between any two vectors, which is necessary for clustering, we used the HDBSCAN’s cosine similarity metric.
We chose HDBSCAN over a K-means clustering algorithm, since we were not initially sure how many clusters were ideal for the dataset, which would be necessary to define when using a k-means clustering algorithm. HDBSCAN is able to determine on its own an ideal number of clusters based on the overall shape and distribution of the vectors across the dataset.
The algorithm identified approximately 20 to 30 clusters, depending on the parameter selections for the minimum cluster size and the number of neighbors expected. We then ran TF-IDF on all the “Brief Circumstances” for each cluster in order to label each cluster with a potential title. Some examples of topic labels were “Cardiopulmonary Arrest / Cardiovascular Disease / Failure” and “Fentanyl Toxicity / Fentanyl Intoxication / Fentanyl.”
We manually reviewed the deaths assigned to each of the clusters, reading through “Brief Circumstances” to determine whether each death belonged in the cluster in which HDBSCAN had assigned it.
Once we had manually gone through each cluster, we froze the entries in each cluster the human reviewer had decided belonged and then re-clustered the unfrozen entries in order to achieve a better understanding of the possible titles for each cluster. We also tried to remove from the clustering cycles as many results indicating unknown causes of death or were still pending autopsy results before a cause of death determination could be made.
This step was made more difficult by the multiple misspellings of the word “unknown.”
While each round helped our understanding of the clusters, we were still left with a rather broad category of “-1”, representing HDBSCAN’s reject pile of unclassified entries, which were not used in assigning cluster labels.
This process resulted in a list of named clusters into which we could then sort the deaths in the dataset. We mapped each of the clusters we had created onto the original “Manner of Death” categories defined by the Justice Department.
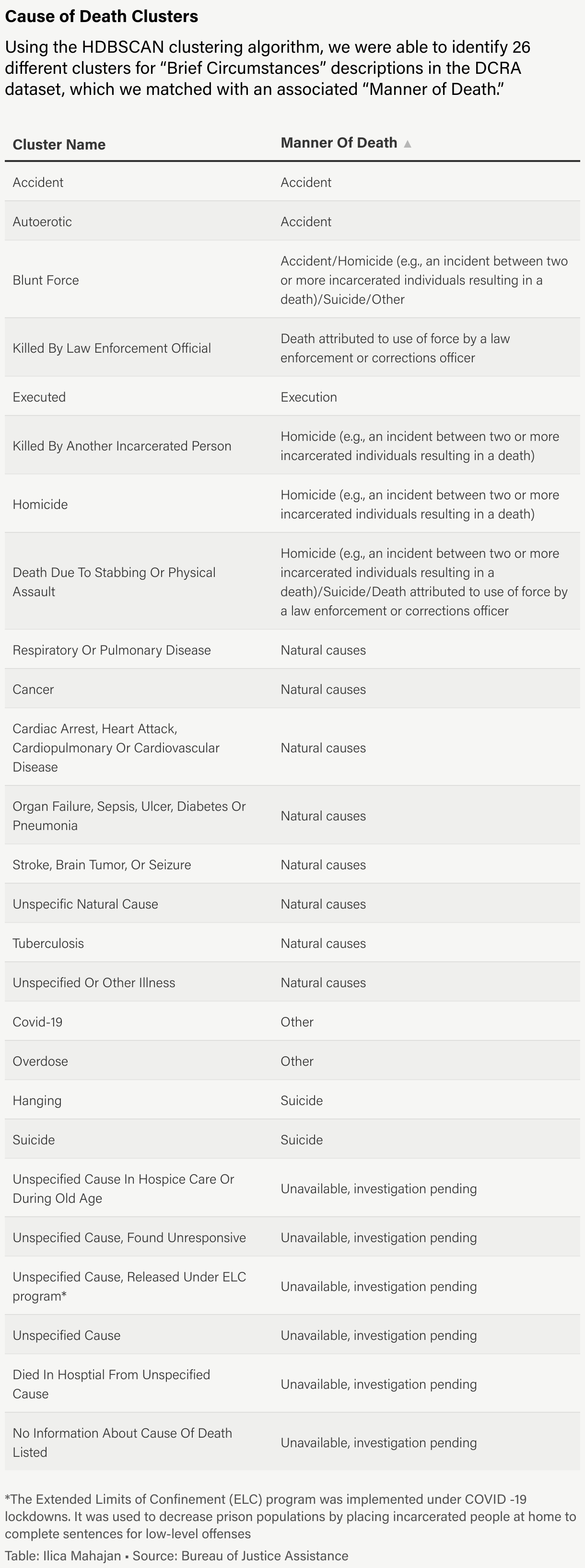
Zeroshot Classification
Next, we used the same OpenAI embedding model to do “zero-shot classification,” which forced each of the “Brief Circumstances” into one of the clusters we defined by calculating the cosine similarity between the vector of a given “Brief Circumstance” and the vector for each of the clusters and selecting the highest score.
This process generated a spreadsheet containing each “Brief Circumstance,” its predicted cluster, the cosine similarity score between the entry and its assigned cluster, its corrected manner of death, and a few flags for human review.
We added a flag calling for a human to review it if:
-
The cosine similarity score was low, less than 0.3, indicating a weak match
-
The gap between the cluster with the highest similarity score and the cluster with the second-highest similarity score was under 0.02, indicating that either of those two clusters could potentially be a good fit for a description of the brief circumstance.
-
There weren’t overlapping words in the predicted label and the brief circumstances.
A low similarity score and a lack of overlapping words, for example, was a sign to a human reviewer that the categorization may not be accurate.
Deaths in the dataset that were flagged in this manner received a human review for potential reclassification.
Entries with insufficient descriptions, like “Gunshot wound to the chest,” which could conceivably be placed in multiple categories — like homicide, use of force by law enforcement or suicide — were left to their original ”Manner of Death” characterization.
Counting
Once we felt confident that all entries were classified correctly, we used the Python library pandas to group entries and count the number in each cluster and update the “Manner of Death” category as necessary.
Limitations
There are several limitations to our analysis that could potential affect how accurately our results reflect the scope of how people are dying in America’s prisons and jails:
-
Our prior reporting on the issue revealed that there are many deaths missing from this dataset. We were not able to determine if these missing deaths were distributed randomly across the ways in which people died, because we did not have a more complete dataset of in-custody deaths for comparison. If deaths of a certain type were systematically underreported, our results could be skewed.
-
Our classifications are dependent on the quality of the "Brief Circumstances" entries, which have wild variation in the level of detail present from one description to the next. In addition, some could be intentionally written to obscure details about the death that could be embarrassing or incriminating for the agency holding the incarcerated person at the time of their death.
-
Around 8,600 rows indicated the cause of death was unknown due to a pending autopsy or toxicology report and the information was never subsequently updated. If certain manners of deaths typically took longer than others to determine cause, our results could be undercounting those types of deaths.
-
California, which has the second-largest number of incarcerated people of any state in the country, does not list a ”Brief Circumstances” for any deaths, due to state privacy rules. We classified all of those deaths as being unknown in their “Manner of Death” because it is impossible for us, or anyone using the federal data, to assess the credibility of determinations based on information submitted by the state.
How to work with us
We have decided not to publicly release the entire list of names, due to privacy considerations for the families of incarcerated individuals. However, if you are a journalist or researcher interested in reporting on, or researching, deaths in custody using this dataset, please fill out this form.
If you’re interested in learning more about reporting on in-custody deaths, check out our guide for journalists, published as part of The Marshall Project’s Investigate This series.
Acknowledgements
Thanks to Jeff Kao at Bloomberg for advising on the technical aspects of the clustering analysis.